
building a scalable benchmark measuring LLM capabilities for vulnerability detection
you want to know whether a language model reasons about a security bug or just recognizes one. the famous CVEs are no help: it has read those, fix and all, so a right answer proves nothing. you want to show it a function it has never seen and see it work out for itself that the addition overflows, or the index runs past the end of the buffer. so you need code the model can't have memorized, a bug you know is still in there, and then you watch the verdict.
and you can't just pull a dataset off the shelf for this. the ones built from real bugs are scraped from public fix commits, BigVul, DiverseVul, PrimeVul and the rest (Fan et al. 2020; Chen et al. 2023; Ding et al. 2025), all of it public and all of it very plausibly in the model's training data already. the other option is synthetic, Juliet and the SARD suites (NIST 2017), where the flaws are hand-injected and the code is narrow and looks like nothing in the wild. and either way the unit is small: one function, sometimes a few, rarely even the whole commit they came out of. ARVO (Mei et al. 2024) is the recent exception that rebuilds the project and replays a real crashing input, and even there a row is usually a single fix commit. so there is no real, unseen, project-scale corpus sitting around to test on.
a different question. you have a transformation that rewrites a function into something unrecognizable that still does the same thing. usually "the same thing" is easy, same inputs, same outputs. but say what you have to keep fixed is one specific bug, a signed overflow, and the output can take care of itself. the standard doesn't define what an overflowing signed int does, it just says undefined; so any transform that only has to respect the standard, the optimizer in your compiler included, can hand the overflow a clean defined answer and quietly take the bug out. how do you preserve a property the language declined to define?
those are two different questions, one about measuring a model and one about transforming code, but they snag on the same thing. both need a way to say "the bug is still there" that doesn't lean on the standard, which goes quiet exactly where the bug lives, and doesn't lean on a model or a commit label, which stop meaning anything the moment the code changes. one check answers both, and it is old and unglamorous: compile the code and run it.
the label
the check is a differential under a sanitizer (Serebryany et al. 2012; LLVM Project 2026). compile the vulnerable function and its patched version with AddressSanitizer and UndefinedBehaviorSanitizer, feed both the input that trips the bug, and watch: the vulnerable one faults, the patched one doesn't. that pair is the label; crash-confirmed, we call it. part of the corpus has it, the rest carry a reasoning trace and nothing mechanical behind it.
here is a minimal version, also the shape of a real row in the corpus (a freetype fix that does the add in an unsigned macro to kill the overflow):
long acc(long a, long b) { /* vulnerable */
return a + b; /* signed overflow is undefined */
}
long acc(long a, long b) { /* patched */
return (long)((unsigned long)a + (unsigned long)b);
}build it under -fsanitize=undefined, call it with a = LONG_MAX, b = 1, and the first one faults while the second stays quiet:
acc.c:2:14: runtime error: signed integer overflow:
9223372036854775807 + 1 cannot be represented in type 'long'
that difference is the whole label, and it comes from behavior; spelling doesn't enter into it. so you can rewrite the function however far you like, recompile, run that same input, and it still answers.
it is also why you can't just lift the label off the fixing commit. 20-71% of the labels in the usual vulnerability datasets are wrong (Croft, Babar, and Kholoosi 2023); PrimeVul re-labeled and de-duplicated one and watched a reported F1 of 68 fall to 3 (Ding et al. 2025). a commit label says a fix touched this function. it doesn't say the bug is still in this rewrite of it. the sanitizer says exactly that, every variant.
obfuscation
rewriting a program so you can't recognize it while it keeps working is, more or less, a solved problem. it is called obfuscation, a corner of software diversity (Larsen et al. 2014), and it is half of what we want here: a way to drag a function away from anything the model saw in training. the overlap is literal, the transforms are the same ones. rename the locals. flatten the control flow into one big dispatch loop (C. Wang et al. (2001) did this first). bury the branches under opaque predicates, conditions that are constant but a pain to work out statically (Collberg, Thomborson, and Low 1997). or virtualize: compile the function down to a little bytecode and ship an interpreter for it. people have measured this stuff for decades; Collberg, Thomborson, and Low (1997) score a transform on potency (how unreadable it gets), resilience (how hard to strip back off), stealth (how much it still passes for normal code) and cost (how much bigger and slower). our surface distance is a rough potency number, the expansion ratio is cost.
take this function:
int sum(int n) {
int s = 0;
for (int i = 0; i < n; i++)
s += i;
return s;
}run it through Tigress (Collberg et al. 2024) with flattening on and you get this (names shortened, its comments and line markers stripped, whitespace tidied):
int sum(int n) {
int s, i;
unsigned long next = 1UL;
while (1) {
switch (next) { /* cases emitted in shuffled order */
case 1UL: next = 2UL; break;
case 3UL: s += i; i++; next = 0UL; break;
case 6UL: return s;
case 0UL: if (i < n) next = 3UL; else next = 6UL; break;
case 2UL: s = 0; i = 0; next = 0UL; break;
}
}
}so obfuscation is aimed the right way. it still isn't what we need, for three reasons.
first, what it actually preserves. an obfuscator preserves behavior: same inputs, same outputs, unreadable shell. but a lot of security bugs are undefined behavior, and undefined behavior has no fixed observable behavior to hang onto in the first place. and it gets worse. the textbook notion of "preserves behavior" is allowed to take an undefined operation and give it a definition, which means it is allowed to delete the bug and still be called correct (Leroy 2009; Lee et al. 2017). preserving the semantics and preserving the bug are two different things, and on the undefined-behavior bugs they part ways.
the cleanest way to see it is the most innocent transform you could pick, a round-trip
through the compiler. lower that overflow function to LLVM IR, emit C back out with
llvm-cbe. in the IR the signed add wears a flag, nsw, no signed wrap, the
compiler noting to itself that overflow is undefined here so it may as well assume it
never happens (attributes trimmed):
define i64 @acc(i64 %0, i64 %1) {
%3 = add nsw i64 %1, %0 ; nsw: signed overflow is undefined here
ret i64 %3
}UBSan instruments exactly the operations that carry that flag, so the flag is the bug. portable C has no way to write "signed overflow is undefined", so llvm-cbe doesn't try; it gives you back the function with the operands turned unsigned and the add run through a plain wraparound helper (declarations elided):
static uint64_t llvm_add_u64(uint64_t a, uint64_t b) {
uint64_t r = a + b; /* defined unsigned wraparound */
return r;
}
uint64_t acc(uint64_t _1, uint64_t _2) { /* the long parameters are now unsigned */
return llvm_add_u64(_2, _1);
}the signed type is gone, and the nsw flag with it, and the add is just an
unsigned add now, fully defined, with nothing left for the sanitizer to catch, so the
side that faulted a second ago runs clean. llvm-cbe did nothing wrong, that is a sound
refinement, and the bug was living in the one gap a refinement is free to close. and
this is the single biggest bug class in the corpus: integer overflow leads, then
underflow and signedness and the shift bugs, all of them undefined behavior. staying in
C doesn't get you out of it either. Tigress ships EncodeArithmetic and EncodeData, which
grind arithmetic into bitwise and mixed boolean-arithmetic identities and dissolve the
overflow just as the round-trip did; and the IR-pass obfuscators like Obfuscator-LLVM
(Junod et al. 2015) rewrite arithmetic for the same reason, so they fail here too.
second, cost. an obfuscator will spend almost anything in size and speed to protect a
binary. virtualize that same six-line sum with Tigress and you get a bytecode
array and an interpreter to walk it (names shortened, body cut):
unsigned char sum_bytecode[109]; /* the function, compiled to bytecode */
/* ... */
while (1) { /* the interpreter, in C */
switch (*pc) { /* one case per bytecode op, over a */
/* ... */ /* stack, the locals, and the pc */
}
}surface distance 0.99, basically total, and across the corpus it runs about 43 times the original size. for a binary you are shipping, fine. for us it is dead on arrival. the thing has to read like a function somebody might actually have written, and stay roughly the size of the original, or it stops being a fair question to put to the model. we want less than an obfuscator wants: move the surface, keep it plausible, keep it small, and don't lose sleep over a determined reverse engineer.
third, the part an obfuscator never has to deal with at all: there is a check it never runs. it has no concept of "the bug stays in". it will happily hand you a variant with the bug gone, as long as the input-output behavior it promised to keep is still there, and for undefined behavior there isn't any such behavior to keep. the code-robustness benchmarks do perturb their inputs, but they confirm the meaning held by asking a human (S. Wang et al. 2023) or by keeping the edit "natural" (Yang et al. 2022), and neither one tells you a specific fault still goes off. we need the other thing, and we need it mechanically, on every variant: recompile, run the trigger under ASan and UBSan, confirm the vulnerable side still faults and the patched side still doesn't. an obfuscator never does that. it is the step that turns "make this unrecognizable" into a different job altogether.
so the engine keeps the obfuscation moves that shift the surface without touching the arithmetic, the structural type-preserving ones, rename and flatten and the opaque-predicate dispatch, and drops the rest: the arithmetic and data encoders, anything that goes through compiler IR, virtualization. the undefined-behavior operation and its operand types get pinned in place, the rest of the function is fair game, and the oracle checks every rung. Tigress stays around as a yardstick for how far distance can go, not as the tool we run; it is closed-source, non-commercial only, and its output has a fingerprint, so it ought to be something you measure against rather than ship.
refinement and equivalence
why is the erasure allowed at all? the asymmetry in the answer is the whole reason the job is hard. call a transform correct, in the ordinary compiler sense, when the output refines the input: take a program P and a transformed P', and on every input the behaviors P' can show are among the ones P can. the catch is what happens on an input where P is already undefined. there the standard promises nothing, so P's set of allowed behaviors is everything, and whatever P' does sits inside it automatically. the refinement holds no matter what P' picks. so on exactly the undefined inputs, a correct transform gets to choose any convenient defined behavior it likes. there is nothing underhand in that; it is the mechanism that makes optimization work at all, the compiler assumes the undefined thing never happens and generates code on that basis (Lee et al. 2017; Lopes et al. 2021).
that is the whole split between being correct and keeping the bug, and it only runs one way. the bug lives on those undefined inputs, so a refinement can quietly send them somewhere harmless, and a transform that does exactly that is still, provably, correct. the converse doesn't hold: nothing about being correct makes the bug stay. for that you would want equivalence, refinement in both directions, P' refines P and P refines P' at once, which forces the behavior sets to match on every input, undefined ones included, and so leaves no room to give undefined behavior a definition. equivalence is stronger than anything a compiler owes you, which is why you won't get it for free out of a compiler or an IR-level tool. CompCert doesn't hide this: the theorem only covers source programs with no undefined behavior, and a verified compiler is explicitly allowed to throw away a computation that was going to go wrong (Leroy 2009).
whether a particular correct transform actually kills a particular bug then comes down to
one thing, does it rewrite the operation into a form that no longer carries the
undefinedness. signed overflow carries it in two places, the nsw flag and the
signed type, and a round-trip through portable C keeps neither, so both go, which is what
you saw in the acc output above. an out-of-bounds read carries no flag like that;
llvm-cbe re-emits the same pointer arithmetic and the same dereference, the bad access
happens, the sanitizer trips. so the line that matters is whether the bug is an assumption
the transform is allowed to throw away, more than whether it is a memory bug or an integer
one.
so the proof that a rewrite kept the bug comes in tiers, from cheap and weak up to dear
and strong. cheapest, and the one we run on every variant, is a per-input witness: the
sanitizer differential on the input that triggers the bug. that is equivalence modulo
inputs (Le, Afshari, and Su 2014), cut down to the single input you care about. a step up, for
small functions, you can run bidirectional translation validation, which proves
equivalence rather than refinement, and Alive2 will do it (Lopes et al. 2021); but it
is intraprocedural, it bounds the loop unrolling, and it has to see the IR before the
nsw flag is stripped, or both sides read as defined and it proves equivalence for
free and tells you nothing. the top tier, a proof that the bug survives on every input,
has no tool you can just pick up, because the default meaning of "correct" is refinement
and refinement lets the bug go. you would have to work in a semantics where "has undefined
behavior of kind K on input i" is an actual predicate, kcc (Hathhorn, Ellison, and Roşu 2015) or
Cerberus (Memarian et al. 2019), and discharge a both-directions obligation on top of
it. that is a research project rather than a pipeline stage. we live on the per-input witness, and
reach for Alive2 when the function is small enough to be worth it.
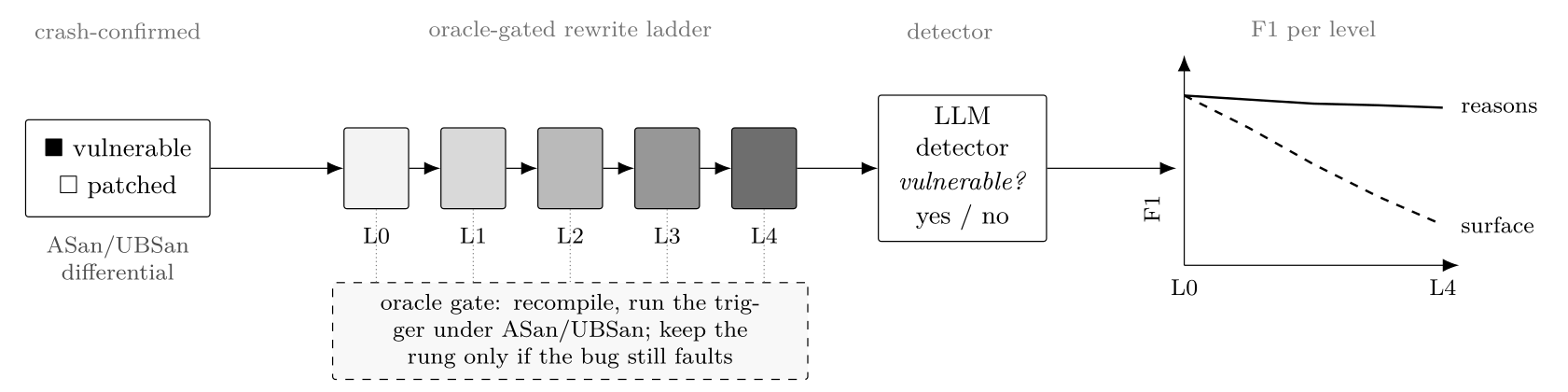
the ladder
the transforms that get through that filter stack up into a graded ladder, each level
adding to the one under it, each one gated so a level only counts for a function if the
bug still fires there. back to that same sum:
L0 the function as written
L1 rename locals
L2 + mangle the function name, encode integer literals
L3 + flatten control flow into a dispatch loop
L4 + guard each case with an opaque predicate
L3 is the dispatch loop from before, the same flattening an obfuscator does, only here the undefined-behavior site is pinned through it and the oracle confirms the bug still fires before the level counts. over the crash-confirmed functions the mean surface distance (one minus a difflib ratio) goes 0.21, 0.41, 0.59, 0.66 across L1 to L4, monotonically, and the output stays around 1.1 times the size it started at. about one function in six drops out at L3 and L4, where the flattener can't lower it on its own, it wants project headers, or a rung below it already broke the build; those get left out instead of mislabeled. set that against Tigress, 0.99 distance at 43 times the size, and it is the sweet spot from earlier: nearly all of the distance, almost none of the cost.
the measurement
once the ladder is there the benchmark almost writes itself: run a detector across L0 to L4 on both sides of every function, vulnerable and patched, and score its F1 per level against the oracle. if it is reasoning about the bug, the F1 holds up as the surface shifts under it. if it was leaning on the surface, the score slides the higher you climb. the patched side at each level is the matched negative, there to catch a detector that just yells "vulnerable" at anything obfuscated. people have already seen this at a single step: detectors up around 70% accuracy can't separate a function from its own fix (Risse and Böhme 2024), and renaming the functions and variables alone flips the verdict about a quarter of the time, 26%, with another 17% from tossing in unrelated library calls (Ullah et al. 2024). the ladder turns that one step into a whole axis.
contamination stops being a thing you worry about and turns into one of the things you are measuring. the clean L0 of a public CVE might just be memorized, so its F1 there is an inflated ceiling, propped up by recall; the obfuscated versions are almost certainly in nobody's training data, so the fall from L0 to L4 on one function is the familiarity effect on its own (Magar and Schwartz 2022; Li and Flanigan 2024). there is one more reading of a sinking curve you have to kill off, that the obfuscated code is simply harder for anyone to read; throw a comprehension probe at the same variants, have the model summarize the function or say what it returns on some input, and that tells the two apart.
the limit comes from the label. a sanitizer sees memory-safety and undefined-behavior bugs and nothing else, so the logic bugs, the auth bugs and the information leaks, none of which trip a sanitizer, get a reasoning trace but no crash-confirmed label and no gated ladder. inside the classes a sanitizer can see, which is most of what a fuzzer turns up anyway, the label is mechanical and survives any rewrite you throw at it. and that is the property that made the two questions at the top, measuring reasoning and holding an undefined bug in place, come down to the same check.
references
Chen, Yizheng, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner. 2023. "DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection." In International Symposium on Research in Attacks, Intrusions and Defenses (RAID). https://doi.org/10.48550/arXiv.2304.00409.
Collberg, Christian et al. 2024. "The Tigress C Diversifier/Obfuscator." https://tigress.wtf/.
Collberg, Christian, Clark Thomborson, and Douglas Low. 1997. "A Taxonomy of Obfuscating Transformations." 148. Department of Computer Science, University of Auckland. https://researchspace.auckland.ac.nz/handle/2292/3491.
Croft, Roland, M. Ali Babar, and M. Mehdi Kholoosi. 2023. "Data Quality for Software Vulnerability Datasets." In IEEE/ACM International Conference on Software Engineering (ICSE). https://doi.org/10.48550/arXiv.2301.05456.
Ding, Yangruibo, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David Wagner, Baishakhi Ray, and Yizheng Chen. 2025. "Vulnerability Detection with Code Language Models: How Far Are We?" In IEEE/ACM International Conference on Software Engineering (ICSE). https://doi.org/10.48550/arXiv.2403.18624.
Fan, Jiahao, Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. "A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries." In International Conference on Mining Software Repositories (MSR), 508-12. https://doi.org/10.1145/3379597.3387501.
Hathhorn, Chris, Chucky Ellison, and Grigore Roşu. 2015. "Defining the Undefinedness of C." In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). https://fsl.cs.illinois.edu/publications/hathhorn-ellison-rosu-2015-pldi.pdf.
Junod, Pascal, Julien Rinaldini, Johan Wehrli, and Julie Michielin. 2015. "Obfuscator-LLVM: Software Protection for the Masses." In IEEE/ACM International Workshop on Software Protection (SPRO). https://crypto.junod.info/spro15.pdf.
Larsen, Per, Andrei Homescu, Stefan Brunthaler, and Michael Franz. 2014. "SoK: Automated Software Diversity." In IEEE Symposium on Security and Privacy (s&p). https://oaklandsok.github.io/papers/larsen2014.pdf.
Le, Vu, Mehrdad Afshari, and Zhendong Su. 2014. "Compiler Validation via Equivalence Modulo Inputs." In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 216-26. https://doi.org/10.1145/2594291.2594334.
Lee, Juneyoung, Yoonseung Kim, Youngju Song, Chung-Kil Hur, Sanjoy Das, David Majnemer, John Regehr, and Nuno P. Lopes. 2017. "Taming Undefined Behavior in LLVM." In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). https://doi.org/10.1145/3062341.3062343.
Leroy, Xavier. 2009. "Formal Verification of a Realistic Compiler." Communications of the ACM 52 (7): 107-15. https://doi.org/10.1145/1538788.1538814.
Li, Changmao, and Jeffrey Flanigan. 2024. "Task Contamination: Language Models May Not Be Few-Shot Anymore." In AAAI Conference on Artificial Intelligence. https://doi.org/10.48550/arXiv.2312.16337.
LLVM Project. 2026. "Clang UndefinedBehaviorSanitizer Documentation." https://clang.llvm.org/docs/UndefinedBehaviorSanitizer.html.
Lopes, Nuno P., Juneyoung Lee, Chung-Kil Hur, Zhengyang Liu, and John Regehr. 2021. "Alive2: Bounded Translation Validation for LLVM." In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). https://doi.org/10.1145/3453483.3454030.
Magar, Inbal, and Roy Schwartz. 2022. "Data Contamination: From Memorization to Exploitation." In Annual Meeting of the Association for Computational Linguistics (ACL). https://doi.org/10.48550/arXiv.2203.08242.
Mei, Xiang et al. 2024. "ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software." https://doi.org/10.48550/arXiv.2408.02153.
Memarian, Kayvan, Victor B. F. Gomes, Brooks Davis, Stephen Kell, Alexander Richardson, Robert N. M. Watson, and Peter Sewell. 2019. "Exploring C Semantics and Pointer Provenance." Proceedings of the ACM on Programming Languages (POPL) 3. https://www.cl.cam.ac.uk/~pes20/cerberus/cerberus-popl2019.pdf.
NIST. 2017. "Juliet Test Suite / Software Assurance Reference Dataset (SARD)." https://samate.nist.gov/SARD/.
Risse, Niklas, and Marcel Böhme. 2024. "Uncovering the Limits of Machine Learning for Automatic Vulnerability Detection." In USENIX Security Symposium. https://doi.org/10.48550/arXiv.2306.17193.
Serebryany, Konstantin, Derek Bruening, Alexander Potapenko, and Dmitry Vyukov. 2012. "AddressSanitizer: A Fast Address Sanity Checker." In USENIX Annual Technical Conference (ATC). https://www.usenix.org/conference/atc12/technical-sessions/presentation/serebryany.
Ullah, Saad, Mingji Han, Saurabh Pujar, Hammond Pearce, Ayse Coskun, and Gianluca Stringhini. 2024. "LLMs Cannot Reliably Identify and Reason about Security Vulnerabilities (yet?): A Comprehensive Evaluation, Framework, and Benchmarks." In IEEE Symposium on Security and Privacy (s&p). https://doi.org/10.48550/arXiv.2312.12575.
Wang, Chenxi, Jonathan Hill, John Knight, and Jack Davidson. 2001. "Protection of Software-Based Survivability Mechanisms." In International Conference on Dependable Systems and Networks (DSN). https://doi.org/10.1109/DSN.2001.941405.
Wang, Shiqi, Zheng Li, Haifeng Qian, Chenghao Yang, Zijian Wang, Mingyue Shang, Varun Kumar, et al. 2023. "ReCode: Robustness Evaluation of Code Generation Models." In Annual Meeting of the Association for Computational Linguistics (ACL). https://doi.org/10.48550/arXiv.2212.10264.
Yang, Zhou, Jieke Shi, Junda He, and David Lo. 2022. "Natural Attack for Pre-Trained Models of Code." In International Conference on Software Engineering (ICSE). https://doi.org/10.48550/arXiv.2201.08698.